If you think that building a product only after you have started selling it to people is a mad idea, we are here to show you great minimum viable product examples that prove the opposite.
MVPs can be any ideas or products that feature only a limited set of functions or capabilities that are still enough to prove your concept in a determined market.
Whether you are working on app development or a vegan dog-treats business, building an MVP may save you time and money on the way to commercializing a finished product, and the definition doesn’t stop there, since you can also ask yourself about minimum viable channels, segments, services or promotion.
Facebook, Dropbox, and Zappos have all in common that they started as minimum viable products, proving that investing tons of money is not always a requirement for launching a big business, but the ability to listen to your market and carefully cater to them according to their feedback of your ideas.
In this article, we will show you what the different types of MVPs are and give you examples so you can get inspired and easily venture out into the wild world of product and service development. We will also explore some minimum viable product examples.
5 Types of Minimum Viable Product Examples That You Can Build on a Low Budget
In the world of startups, it is common to see state-of-the-art tech that no one really knows what to use for. This probably happens because creators often focus on bringing finished products to the market without first considering if consumers really want them, and here’s where MVPs play a vital role in redefining business models.
Think about the overhyped Google Glasses that were about to be released in May 2014 for $1,500. The company focused so much on product features such as using a VR platform via voice commands (which sounds really nice) that they forgot people didn’t want to wear glasses in the first place.
There are two classifications of MVP: low fidelity MVPs serve for better understanding your consumer’s needs and see if your solutions are worth enough for solving their problems, while high fidelity MVPs focus more on how much would they pay for your product and getting early adopters that can later help you redefine your value proposition as you listen to them.
Choosing between high fidelity or low fidelity MVPs depends on how much time you have and how much are you willing to spend on this stage of your product development.
1. Landing Page
A landing page is a website designed to motivate visitors to carry out a specific task (give you their email, see your products or buy them) once they have clicked on a marketing communication such as an Instagram ad. This is a great way to show them what you have and prove if your communications are going the right way.
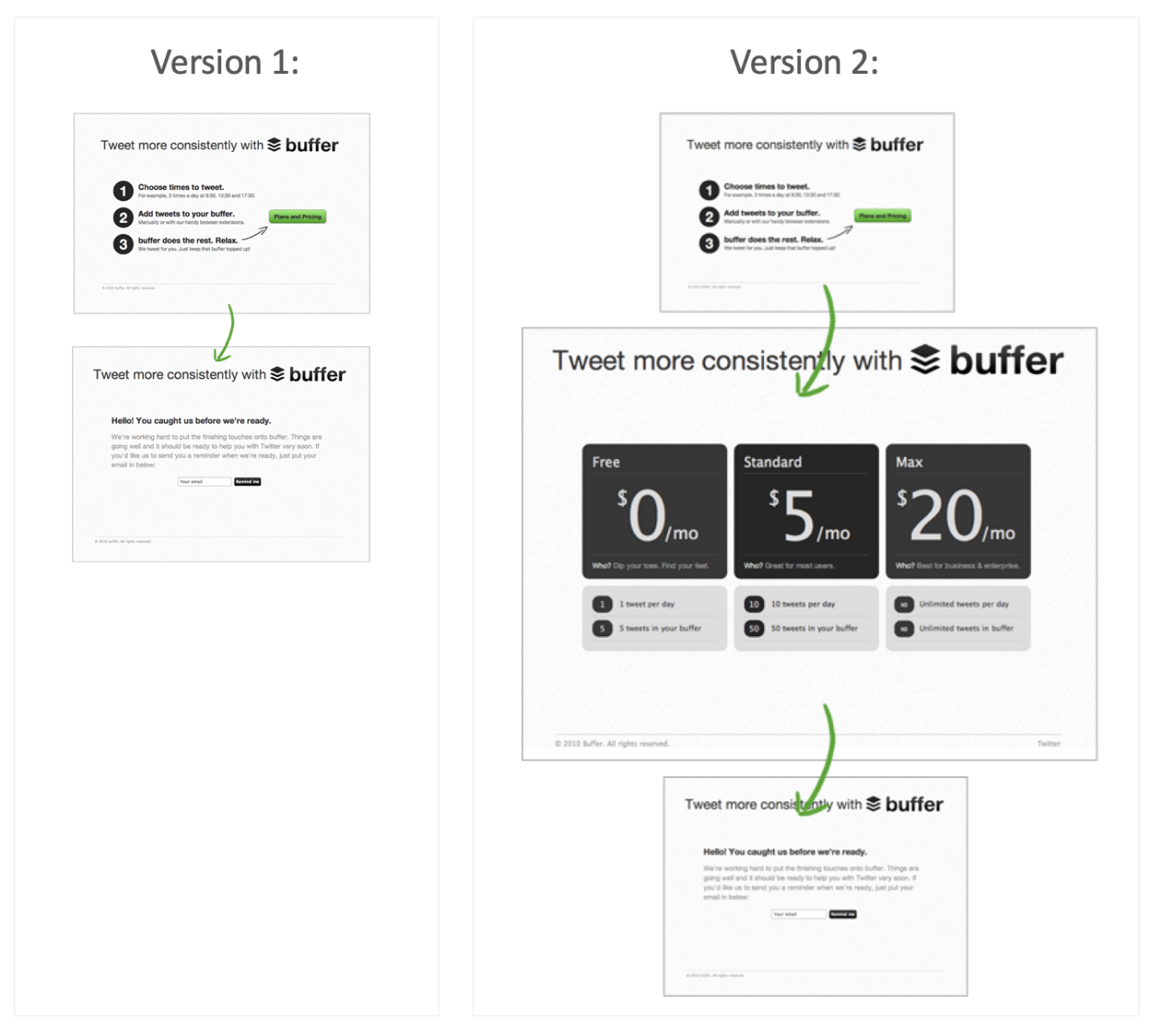
Buffer, an app designed for scheduling social media posts, is an extraordinary example of this. Their MVP was a landing page that explained the platform’s capabilities and encouraged people to sign up. However, by that time the app actually didn’t exist at all so customers were shown a message saying the service wasn’t ready and that they would be receiving updates.
Once the creators had a database of enough possible users, they started asking them if they would be willing to pay for the service. What they did is testing that hypothesis by adding prices to the landing page. This allowed them to see how many visitors would actually turn into paying customers.
2. Short videos (Dropbox)
Short videos are one of the most popular MVPs out there. They are zero-risk, cheap to elaborate, and effective for communicating complex ideas surrounding your product and services. They are so versatile you can post them on MVP platforms such as GoFundMe, show them to investors and even people on your way.
You would be amazed to know that Dropbox, which has a market cap of 11.9 billion, started as a 2-minute MVP that explained with paper figures how the cloud service worked.
3. Ad campaigns and digital mock-ups
Ad campaigns allow you to test if you are targeting the right audiences. With platforms such as Google and Facebook ads, you can even measure what are the features of your products that people appreciate.
Using CGI imagery on your ads is a creative way of testing your product’s appeal. You can do this for a fraction of the real cost of manufacturing a real product by hiring a designer at a platform such as upwork.com.
If people actually try to buy the product once they have reached your website through your social media ads, you can tell them the product is out of stock, and even give them a coupon, a gift card or a discount code they can later use when the product is available. This is great for proving if the market wants the product before you go to the manufacturing process.
A great example of an MVP that started as a crowdfunding project is the board game Kingdom Death Monster, which raised $12.4 million from more than 19,000 people back in 2016. Back then, they used clear images and a great explainer video before they had started production.
5. “The Wizard of Oz”
This MVP consists of creating an illusion of a product, which translates into people thinking they are experiencing the real thing while you are actually using a human resource behind the
curtains. The Wizard of Oz is adequate for analyzing the demand of a product while you keep the operational costs low.
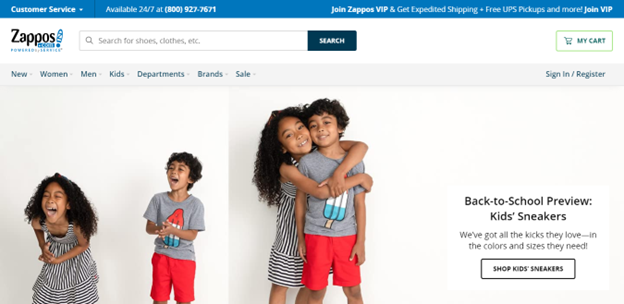
A noteworthy example of The Wizard of Oz is Zappos, a shoe company that was acquired by Amazon in 2009 for $1.2 billion. This business started with its founder Nick Swinmurn posting pictures online of shoes that he didn’t have in stock but that were for sale in stores nearby his home. Once customers bought him a pair of shoes through his simple website he would manually process the order, buy the shoes and send them.
Do you want to avoid problems in software development? You may need to know what the best code review practices are. In this case, we will tell you which strategies are necessary for you to understand how to program in the best possible way.
The importance of knowing the best code review practices
No matter what language you program in: you should always review the code. This is an essential activity for developing any kind of software. You may not like to do it, but it is necessary to ensure high final quality in all your work.
If you do so, you will save a lot of time in possible complications later on. In other words, prevention is the best way to avoid problems. Well, here we will tell you why it is necessary to do a code review regularly:
We all make mistakes. Even the most genius coder is prone to mistakes. So, if you’re having a bad day, have had little sleep, or simply missed something, you should review what you’ve written.
It is a way to improve teamwork. When a code review is done, programmers usually collaborate. This situation implies a better predisposition to strengthen group bonds.
You will not always do what is necessary. This can be seen in disorganized projects or where the requirements are quite ambiguous. In those cases, you will interpret things when programming, which may not be appropriate in the final code. If you review it, you will be able to detect those flaws.
You can learn. In the same way, all programmers learn by trial and error. So, if you can catch your own mistakes, you will not only be learning how things are done properly. You will also be able to understand your misinterpretation of the facts, something that will ensure that the mistake will not be repeated.
What things should you keep in mind when reviewing the code?
Ideally, you should always be able to review everything. However, that would involve a huge amount of development time. Therefore, we think you may want to consider the following issues:
Functional objective. You should always review those parameters that you are currently working on. Similarly, you should also check only what is necessary. Reviewing everything will be too much work because you will always think that there is something to change. For example, if you launch an MVP, you may only check the primary functions.
Nomenclatures. The nomenclatures must be appropriate. When programming, you can overlook this. However, it should always be implemented in the review. There should be no typing errors, so you should always check that they follow the proper conventions.
Logic. It will depend on the language you use, but the control logic must be appropriate for each case. For example, if you copy code from other places, it is essential that it makes sense with the project and that you avoid any problems it may have.
Future mistakes. You are probably proud of the work you have done. However, you should think pessimistically: what are the possible problems that could occur? If you think about it that way, you will have a relevant preventive attitude that will avoid mistakes in the future.
How much and how should you check?
The truth is that there is no universal answer to this. The code review will be different depending on the size of the systems you have to analyze. That is, a mega-project involving years of development is not the same as a small piece of the software done in a couple of weeks.
Therefore, it is something that you will have to work with your development team since all of you should find the most appropriate methods. Anyway, the usual ranges are between 60 minutes and 2 hours, according to what ReviewPad indicates, but it will always be subjective.
Now, one of the most common ways to do this is through version control systems. For example, in the flow of code merges, when a new line is accepted, a review should be done. If you do it this way, you will see greater efficiency over time.
You must keep track of the time it will take you to do the review, as sometimes taking longer than necessary can be negative for the team. On the other hand, you can take advantage of code viewers to make the necessary revisions, as highlighted from GitHub.
The important thing is that the code is always adapted to the requirements you have regarding the project. This is where knowledge of your business comes into play. This problem occurs because they sometimes confront their wants with the needs of their business. In such a case, you can always ask for third-party opinions to find out which is the best way to go.
In short, you already know the best code review practices. If you manage to incorporate these habits consistently, we assure you that you will have better code results.
Are you learning to program and need some help? Don’t worry: we’ve all been there. In this case, we will tell you which are the best ideas for coding in Python. We assure you that, after reading this article, you will have better references to make your work routine or learning more bearable.
Programming in Python: an excellent option.
First of all, something essential: Why should you choose Python over the other options? Let’s start by describing its virtues. According to Simplilearn, Python is one of the most popular programming languages of the moment. Although it was created in the 1980s, today it is extremely useful and versatile for different projects.
Now, why might it be a great option to learn it? According to TechVidvan, one of its main strengths is that it’s easy to read, learn and write. After all, those will be the procedures you will be doing both when learning and working. Therefore, if you have never had experience in programming languages, this may be your option.
There is also the job field to consider. Python is one of the most sought-after languages by employers. So, this means one thing: that, if you learn Python, you will be able to get a stable and quality job. But that’s not all! There is also an immense virtue, which is its flexibility.
As it is a general-purpose language, it can be used for different projects. It is not a specific language for web development, for example. In fact, with Python, you will be able to create all kinds of programs and tools. Moreover, Python is interoperable with other languages, such as Java, C, or R.
All of this means that Python can be a perfect solution for those who want to get started in programming. If you want to program, but don’t know specifically what to do, learning Python will give you a general overview of this. Also, once you know your tastes, you can specialize in a particular branch.
Essential tips for coding in Python.
That said, it is also likely that you want to know some secrets to learn how to program in this language. Here we will tell you the most important ones:
Write in code daily.
This is one of the perfect tips for those who are taking their first steps in Python. Perseverance is key to success in learning this language. You might start, but then you don’t have the motivation to continue. This is a mistake! To learn Python you need to write every day.
Memory is key to learning to program and you don’t need to take too much time either. For example, you could consider starting for 30 minutes every day. From a certain point on, you will feel looser and you will be able to perform more and more complex developments. You already know: consistency is very important.
Don’t forget to take notes.
Yes, we know that many doubts will arise while you are writing code. The truth is that you shouldn’t keep those questions in your head: write them down! When you write them down, you are reminding your brain that there are things you need to find out. Fortunately, the Internet can give you the answers.
Python is one of the programming languages with the best communities. Being open-source, you will also have many resources to take advantage of. In addition, it is important to keep in mind that doubt can help you improve your knowledge. Therefore, you should awaken your “curious” side.
Interact with databases.
This is a slightly more technical tip, but just as important. When you learn Python, you’re going to have to interact with basic data structures, such as dictionaries, strings, or lists. You might also be debugging an application. Consequently, the Python Interactive Shell is going to be your best friend.
Rest is also important.
Python is a truly engaging language. Since it has a low difficulty curve, you might be able to do a lot of things in a short time. That might make you want to learn more and more, but don’t forget to rest! A developer who is not very “lucid” may have a lower frustration tolerance and be less productive.
Don’t get frustrated by mistakes.
We know that making mistakes is a bad thing, but it’s also part of being human. And you have to accept the reality: you will make mistakes once, twice, a hundred times… You can have many years of experience and make basic mistakes. What’s important is to take notes to avoid repeating them in the future.
In short, you have seen that coding in Python can be a great opportunity for those interested in programming. If you follow these tips, your experience is likely to be very positive and you will be able to create great things. We hope this article has been helpful to you!
In a world full of information, organizations feed on data to make all kinds of decisions. Whether operational or strategic resolutions, decisions on logistics, marketing, or finance, data takes a crucial role in this process. The awareness and use of customer data management systems, management information systems, and big data is growing. But data management is not an easy task. Data is stored and manipulated in databases. We can understand that databases, then, represent a fundamental pillar for companies. A correctly-designed database offers customers admission to crucial information. By following the standards and best practices we’ll discuss in this article, you’ll be able to layout a database graph that works nicely and fits your organization’s needs.
What are the components of databases?
Databases are made up of different elements that give life to the interactions between data. We can identify three major components of a database:
1. On the one hand, tables represent a set of homogeneous data with a defined structure. Data is organized into fields (also known as columns) and records (also called rows). Having different tables within a database can be very useful since its correct administration helps to avoid data redundancy and to optimize processes.
2. As the second fundamental pillar of database management, we must mention the relationships between tables. These relationships are links to one or more tables from a field that they share. This field, generally called a key, can represent an identification that allows recognizing the specific record that each row represents. In this way, it is possible to combine different tables to take advantage of their interrelationships.
3. Last but not least, we have the normalization of databases. It is a necessary process for a database to be used optimally. Thanks to it, we can focus on avoiding data redundancy and guaranteeing their referential integrity. Normalization is the process that allows one table to communicate with another and for the data and information type to be compatible. It can also help us to interconnect different databases to take advantage of their joint management.
The interactions between the tables occur thanks to relational algebra. These are all the logical and mathematical operations that work at the back end of a database management system. It allows us to create a relationship between tables, allowing us to retrieve data efficiently.
Relational Schema and how to design databases.
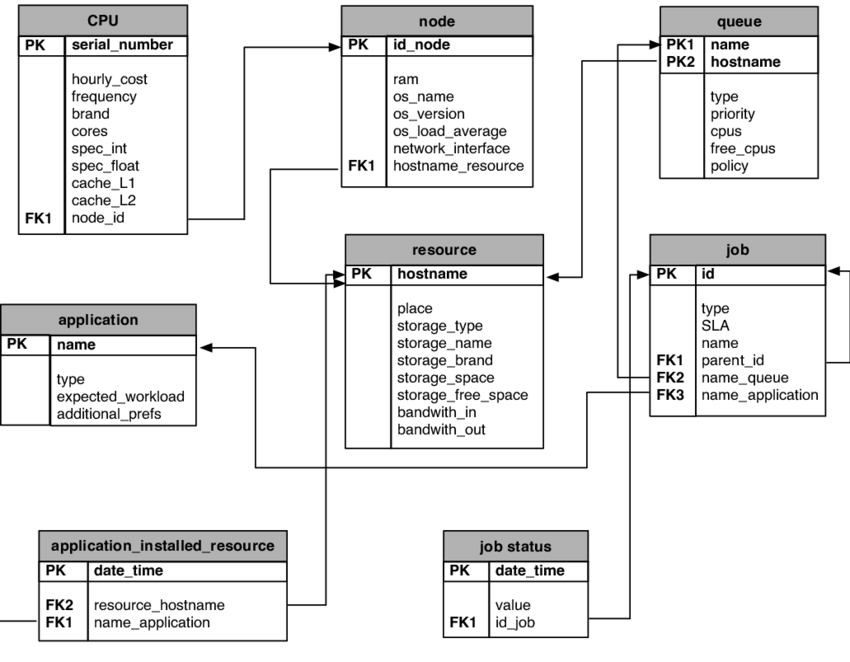
A relational Schema is a graphical representation that allows a data architect to have a reliable idea of how the database must be organized. It is a super useful graphic in the process of planning the structure of a database. It is made up of the tables, the interactions between them, and the different keys that allow them to be used together.
To build a relational schema, we must indicate the following elements on the graph:
Each table, represented as an individual rectangle. For example, a company might have one table with product information, one with customer information, one with production costs, one with sales costs, and one with sales information. These five tables could interact in a database.
Each column of each table, which will be a line within each square. For example, in a table with product information, we might have the following columns: product ID, product name, product brand, product type, product color, and product size.
The primary keys. This is a column (or set of columns) whose value exists and is unique for every record in a table. Surely, reading the concept of the primary key, you can imagine that a common example is the ID of a product or a customer.
The foreign keys. These are columns that identify the relationship between tables. Generally, the primary key of one table is used as the foreign key of another. For example, a table with sales information can use the product ID column as a foreign key to look up product information in another table.
The relationships between the columns, that tell you how much of the data from a foreign key field can be seen in the primary key column of the table that the data is related to.
The types of relationships:
One-to-many: one value from a column under a certain table can be found many times in a column from another table.
One-to-one: each unique value of a column of a table can only appear once in a certain column of another table.
Many-to-many: there is no restriction on the number of times the values can be repeated.
It seems very complicated, but with a little practice, a developer becomes adept at creating databases using this tool. At Huenei we always structure the databases of our projects using relational schemas, since they help us to enhance the operation of our software products.
As you can see, the correct management of these databases could allow a company to reduce the redundancy and inconsistency of data, reduce the difficulty for interested parties to access them, avoiding data isolation. Additionally, database administration focuses on correcting anomalies in concurrent access, reducing security problems, and also data integrity and consistency.
Relational schemas help software factories achieve smoother and more efficient development!
How to scale up your tech startup with software development outsourcing.
The continuous growth of your startup can be both exciting and scary at the same time. This is what all tech companies dream of, but growth does not come easy. If building a tech startup is tough, trying to scale it is even tougher. Startups can’t scale if they don’t get the skills they need.
If you want your business to grow, then you would probably need to grow the number of people working to deliver value to your customers. In the fast-paced world of technology, scaling up may seem like an easy task. You may think you just need to hire a few more developers or keep on adding new UI designers to your team. But scaling up can be a difficult endeavor, especially for startup companies. Let’s explore a better alternative: nearshore software development outsourcing.
Challenges when scaling a business
At Huenei, we worked with over 100 clients, who managed to achieve their desired results in terms of software product development, which helped them increase the value offered to their clients and, consequently, their economic benefit. Having worked with many different startups, we realized there were a lot of challenges when scaling a business. Here are some of the most common hurdles companies (especially startups) face:
The opportunity cost of not devoting time to scaling your business.
Not delegating, and leaving a small group of managers overwhelmed with work.
Not having enough open headcount for hiring.
Having the wrong focus.
Not contracting the right service suppliers.
Underestimating how much work and resources it would take to scale and to keep that growth going.
Hiring staff vs. outsourcing
If you concluded that you need to increase your work team to offer more value to more clients and achieve better business and economic results, you may be overwhelmed.
At first, hiring new collaborators could seem attractive. It is an alternative chosen by many organizations that are committed to building an internal team. On many occasions, this can bring very good results… But the main challenge that arises is the uncertainty regarding the way of working, the results to be achieved, and the associated costs.
On the one hand, when hiring new teams, people do not know each other and may need some time to start working together harmoniously. In addition, these teams will require constant attention and direction from your company’s management. Following this line, you do not know until you have gone through a couple of specific projects if the results will be optimal. Finally, the costs associated with hiring staff are often very high!
Let us share with you some great news: There’s a way to avoid wasting money and resources on developing in-house teams, so a startup can grow without huge investments. It’s more advantageous from a quality point of view, as well as taking into account the associated costs, to contract a company that takes care of development. If you own or work for a tech startup and you need to boost your operations and your services, you can contract nearshore development services. They will dramatically improve your value proposition and boost your strategy.
In today’s market, where outsourcing is so popular, the options and opportunities for tech startups planning to scale are unlike before.
Grow your business with nearshore software development outsourcing
So, you have a growing business, but how can you scale it up into something bigger? There are countless ways to scale up your company, including hiring personnel, partnering with other businesses, and contracting nearshore software development services.
Rapidly growing tech startups still face the same challenges as small ones: how can you grow on results without growing on costs? As a technology entrepreneur or businessperson, at some point, you will need to be able to scale up your team from a small one to a larger one.
As we have discussed above, outsourcing represents great opportunities and benefits for your company. First of all, your product’s development is performed by a team with extensive experience working on a variety of development projects. In addition, this team adapts its agile way of working to the structure, times, and preferences of your organization. Last but not least, you’ll get better, faster, and more cost-effective results than ever before. Why hire a whole team and grow your payroll when you can get better results with a more efficient investment?
In conclusion, it is important to grow your team to scale up your company, but hiring personnel does come at a cost. You will want to consider the tradeoffs and, most likely, conclude that contracting an outsourced service will offer you the same results (or even better ones), also allowing you to make your costs, your times, and your operations more efficient.
Now it is your turn to make a decision. Outsourcing may be the ideal option that your business needs to grow and scale in a hyper-competitive industry such as technology. Don’t let your business goals get away from you.
Get directly to your mail the latest trends and news in Software Development, Mobile Development, UX / UI Design and Infrastructure Services, as well as in the management of Dedicated Teams and Turnkey Projects remotely.
Subscribe to our mail and start receibing all of our information.