
Data has become a vital element for digital companies, and a key competitive advantage. However, the volume of data that organizations currently have to manage is very heterogeneous and its growth rate is exponential. This creates a need for storage and analysis solutions that offer scalability, speed and flexibility to help manage these massive data volumes. How can you store and access data quickly while maintaining cost effectiveness? A Data Lake is a modern answer to this problem.
This series of articles will look into the concept of Data Lakes, the benefits they provide, and how we can implement them through Amazon Web Services (AWS).
What is a Data Lake?
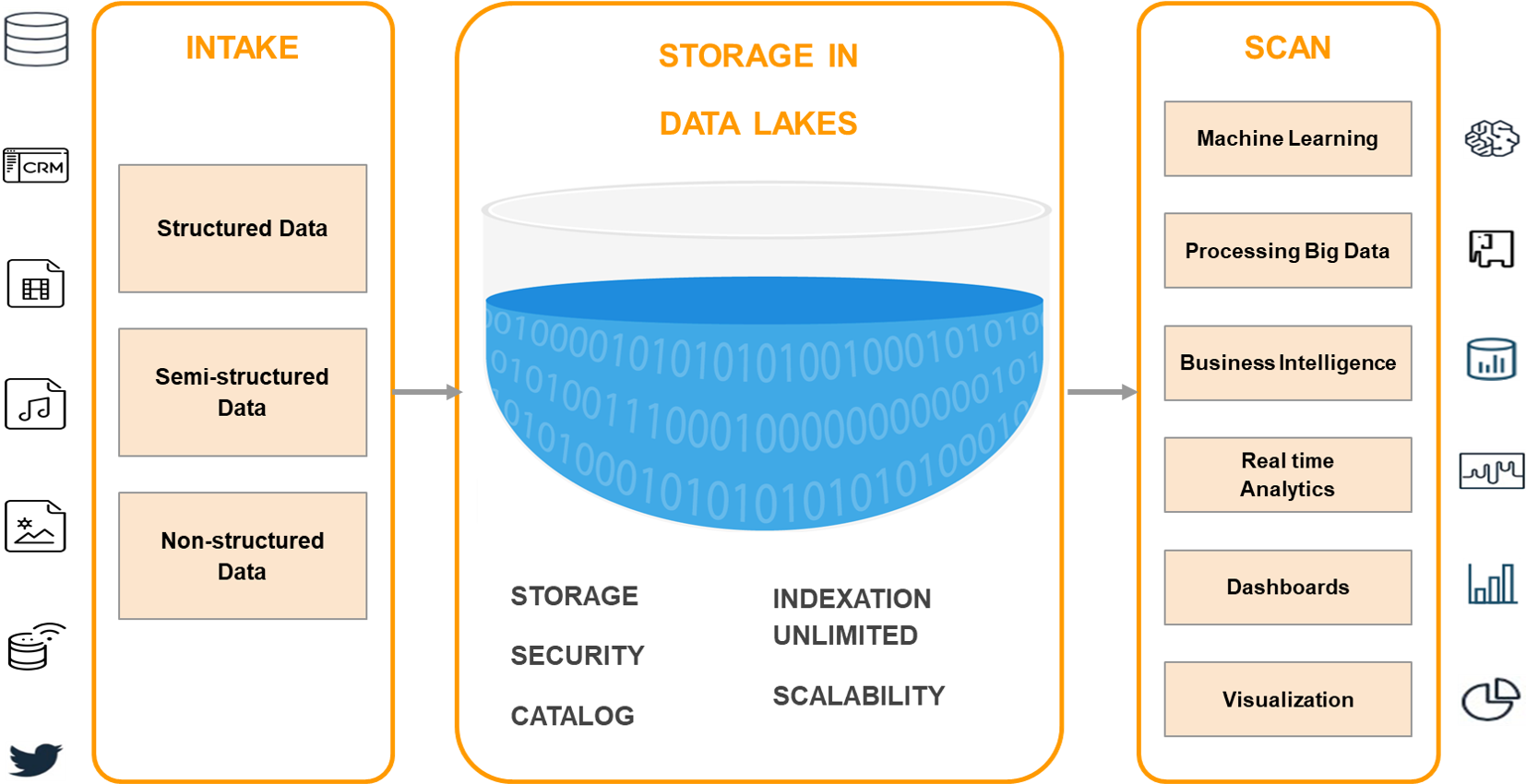
A Data Lake is a centralized storage repository that can store all types of structured or unstructured data at any scale in raw format until needed. When a business question arises, the relevant information can be obtained and different types of scans can be carried out through dashboards, visualizations, Big Data processing and machine learning to guide better decision-making.
A Data Lake can store data as is, without having to structure it first, with little or no processing, in its native formats, such as JSON, XML, CSV, or text. It can store file types: images, audio, video, weblogs, data from sensors, IoT devices, social networks, etc. Some file formats are better than others, such as Apache Parquet, which is a compressed column format that provides very efficient storage. Compression saves disk space and I/O access, while the format allows the query engine to scan only the relevant columns, reducing column time and costs.
Using a distributed file system (DFS), such as AWS S3, allows to store more data at a lower cost, providing multiple benefits:
- Data replication
- Very high availability
- Low costs at different price ranges and multiple types of storage depending on the recovery time (from immediate access to several hours)
- Retention policies, allowing to specify how long to keep data before it is automatically deleted
Data Lake versus Data Warehouse
Data Lakes and Data Warehouses are two different strategies for storing Big Data, in both cases without being tied to a specific technology. The main difference between them is that, in a Data Warehouse, the data scheme is pre-established; you must create a scheme and schedule your queries. Powered by multiple online transactional applications, data has to be converted via ETL (extract, transform and load) to conform to the predefined scheme in the data warehouse. In contrast, a Data Lake can host structured, semi-structured, and unstructured data and has no default scheme. Data is collected in its natural state, requires little or no processing when saved, and the scheme is created during reading to meet the processing needs of the organization.
Data Lakes are a more flexible solution adapted to users with more technical profiles, with advanced analytical needs, such as Data Scientists, since a level of skill is needed to be able to classify the large amount of raw data and easily extract its meaning. A data warehouse focuses more on Business Analytics users, to support business inquiries from specific internal groups (Sales, Marketing, etc.), by owning the data already curated and coming from the company’s operating systems. In turn, Data Lakes often receive both relational and non-relational data from IoT devices, social media, mobile apps, and corporate apps.
When it comes to data quality, Data Warehouses are highly curated, reliable, and considered the core version of the truth. On the other hand, Data Lakes are less reliable since data could come from any source in any condition, be it curated or not.
A Data Warehouse is a database optimized to analyze relational data, coming from transactional systems and business line applications. They are usually very expensive for large volumes of data, although they offer faster query times and higher performance. Data Lakes, by contrast, are designed with a low storage cost in mind.
Some of the legitimate criticism Data Lakes have received is:
- It is still an emerging technology compared to the strong maturity model of a Data Warehouse, which has been in the market for several years.
- Data Lakes could become a “swamp”. If an organization has poor management and governance practices, it can lose track of what exists at the “bottom” of the lake, causing it to deteriorate and making it uncontrolled and inaccessible.
Due to these differences, organizations can choose to use both a Data Warehouse and a Data Lake in a hybrid deployment. One possible reason would be adding new sources or using the Data Lake as a repository for everything that is no longer needed in the main data warehouse. Data Lakes are often an addition or evolution to an organization’s current data management structure rather than a replacement. Data Analysts can use more structured views of the data to get the answers they need and, at the same time, Data Science can “go to the lake” and work with all the raw information as necessary.
Data Lake Architecture
The physical architecture of a Data Lake may vary, since it is a strategy applicable by multiple technologies and providers (Hadoop, Amazon, Microsoft Azure, Google Cloud). However, there are 3 principles that make it stand out from other Big Data storage methods, and they make up its basic architecture:
- No data is rejected. They are loaded from multiple source systems and preserved.
- Data is stored in an untransformed or nearly untransformed condition, as received from the source.
- Data is transformed and a scheme is adapted during analysis.
While information is largely unstructured or geared to answering specific questions, it must be organized as to ensure that the Data Lake is functional and healthy. Some of these features include:
- Tags and/or metadata for classification, which can include type, content, usage scenarios, and groups of potential users.
- A hierarchy of files with naming conventions.
- An indexed and searchable Data Catalog.
Conclusions
Data Lakes are becoming increasingly important to business data strategies. They respond much better to today’s reality: much larger volumes and types of data, higher user expectations and a greater variety of analytics, both business and predictive. Both Data Warehouses and Data Lakes are intended to coexist with companies that want to base their decisions on data. Both are complementary, not substitute, and can help any business to better understand both markets and customers, as well as promote digital transformation efforts.
Our next article will delve into how we can use Amazon Web Services and its open, secure, scalable, and cost-effective infrastructure to build Data Lakes and analytics on top of them.