
Overall Flow
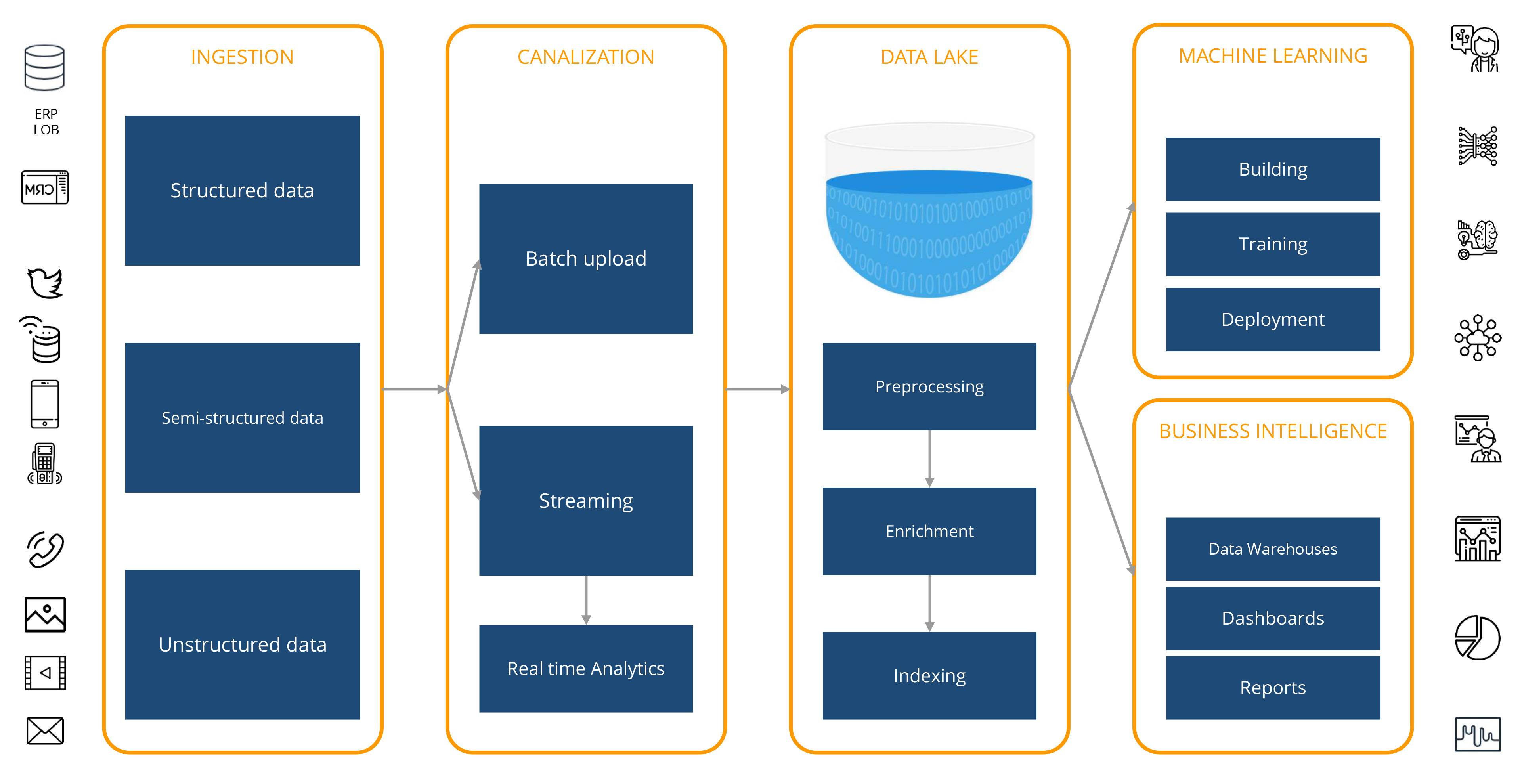
Data Lakes support the needs of our applications and analytics, without the need to constantly worry about increasing storage and computing resources as the business grows and the data volume increases. However, there is no magic formula creating them. Generally, they involve dozens of technologies, tools and environments. The diagram below shows the overall flow of data, from collection, storage and processing, to the use of analytics via Machine Learning and Business Intelligence techniques.
Services supported by AWS
AWS provides a comprehensive set of managed services that help build Data Lakes. Proper planning and design are necessary to migrate a data ecosystem to the Cloud, and understanding Amazon’s offerings is critical. Below are only a few of the most important tools at each stage of the flow.
Collection
The first step is to analyze the goals and benefits you want to achieve with the implementation of an AWS-based Data Lake. Once the plan is designed, data must be migrated to the Cloud, taking into account its volume. You can easily accelerate this migration with services such as Snowball and Snowcone (edge devices for storage and computing) or DataSync and Transfer Family, to simplify and automate transfers.
Channeling
In this step, you can operate in 2 modes: Batch or Streaming.
In Batch Loading, AWS Glue is used to extract information from different sources, at periodic intervals, and move them into the Data Lake. It usually involves some degree of minimal transformation (ELT), such as compression or data aggregation.
For Streaming, data generated continuously from multiple sources, such as logging files, telemetry, mobile applications, IoT sensors and social networks, are collected. They can be processed during a circular time window and channeled into the Data Lake.
Real-time analytics provides useful information for critical business processes that rely on streaming data analysis, such as Machine Learning algorithms for anomaly detection. Amazon Kinesis Data Firehose helps perform this process from hundreds of thousands of sources in real time, rather than uploading data for hours and processing it at a later stage.
Storage and Processing
The core service in any AWS Data Lake is Amazon S3, which provides high scalability storage, excellent costs and security levels, thus offering a comprehensive solution for different processing models. It can store unlimited data and any type of file as an object. It allows you to create logical tables and hierarchies from folders (for example, by year, month, and day), allowing the partition of data in volume. It also offers a wide set of security functions, such as access controls and policies, encryption at rest, registration, monitoring, among others. Once the data is uploaded, it can be used anytime, anywhere, to address any need. The service supports a wide range of storage classes (Standard, Smart, Rare Access), each with different capacities, recovery times, security and cost.
AWS Glacier is a service for secure archiving and backup management at a fraction of the cost of S3. File recoveries can take from a few minutes to 12 hours, depending on the storage class selected.
AWS Glue is a managed ETL and Data Catalog service that helps find and catalog metadata for faster queries and searches. Once Glue points to the data stored in S3, it analyzes it using automatic trackers and records its schemes. Glue is designed to perform transformations (ETL/ELT) using Apache Spark, Python scripts and Scala. Glue has no server; therefore, there is no infrastructure configured, which makes it more efficient.
If the contents of Data Lake need to be indexed, AWS DynamoDB (NoSQL database) and AWS ElasticSearch (text search server) can be used. In addition, by using AWS Lambda features, activated directly by S3 in response to events such as uploading new files, processes can be triggered to keep your Catalog up to date.
Analytics for Machine Learning and Business Intelligence
There are several options for massive Data Lake information.
Once data has been catalogued by Glue, different services can be used in the client layer for analytics, visualizations, dashboards, etc. Some of these are Amazon Athena, an interactive serverless service for ad hoc exploratory queries using standard SQL; Amazon Redshift, a Data Warehouse service for more structured queries and reports; Amazon EMR (Amazon Elastic MapReduce), a managed system for Big Data processing tools such as Apache Hadoop, Spark, Flink, among others; and Amazon SageMaker, a Machine Learning platform that allows developers to create, train and implement Machine Learning models in the cloud.
With Athena and Redshift Spectrum, you can directly query the Data Lake in S3 using the SQL language in the AWS Glue Catalog, which contains metadata (logical tables, schemes, versions, etc.). The most important aspect is that you only pay for the queries executed, depending on the scanned data volume. Therefore, you can achieve significant performance and cost improvements by compressing, partitioning, or converting data into a column format (such as Apache Parquet), as each of those operations reduces the amount of data Athena or Redshift Spectrum should read.
AWS Lake Formation
Building a Data Lake is a complex, multi-step task, including:
- Identify sources (Databases, files, streams, transactions, etc.)
- Create the necessary buckets in S3 to store data with the applicable policies.
- Create the ETLs that will carry out the necessary transformations and the corresponding administration of audit policies and permits.
- Allow Analytics services to access Data Lake information.
AWS Lake Formation is an attractive option that allows users (both beginners and experts) to immediately start with a basic Data Lake, eliminating complex technical details. It allows real-time monitoring from a single point, without having to go through multiple services. One strong aspect is cost: AWS Lake Formation is free. You will only be charged for the services you invoke from it.
It allows loading from various sources, monitoring flows, configuring partitions, enabling encryption and key management, defining transformation jobs and monitoring, reorganizing data in column format, configuring access control, eliminating redundant data, relating linked records, gaining access and auditing access.
Conclusions
These 2 articles looked into the definition of Data Lakes, what makes them different from Data Warehouses and how they can be deployed on the Amazon platform. CTO can be significantly reduced by moving your data ecosystem to the cloud. Suppliers such as AWS add new services continuously, while improving existing ones and reducing costs.
Huenei can help you plan and execute your Data Lake initiative in AWS, in the process of migrating your data to the cloud and implementing the analytics tools necessary for your organization.