
by Huenei IT Services | Jul 28, 2026 | Data
Chile tiene hoy 557 soluciones fintech operando en su territorio, un marco regulatorio considerado el más completo de América Latina junto con Brasil, y el Sistema de Finanzas Abiertas postergado a julio de 2027.
Ese año adicional no es un obstáculo. Es una ventana.
En este whitepaper analizamos el estado real del ecosistema financiero chileno: los datos del Mapa Fintech Chile 2026, la línea de tiempo regulatoria del SFA, la comparativa regional, y lo que significa para bancos, aseguradoras y cooperativas que todavía están decidiendo cuándo empezar a construir.
La regulación ya está escrita. La arquitectura, en la mayoría de las instituciones, todavía no.

by Huenei IT Services | Jul 16, 2026 | Data
La pregunta que casi nadie se hace correctamente
Cuando una institución financiera en LATAM empieza a hablar de Open Finance, la conversación suele abrirse con la misma pregunta: ¿cuándo nos va a obligar la regulación y cuánto va a costar cumplir?
Es una pregunta comprensible. Los equipos de compliance y tecnología necesitan planificar y presupuestar. Pero es, casi siempre, la pregunta equivocada.
Las instituciones que se enfocan en ella llegan exactamente donde esa pregunta las lleva: al mínimo cumplimiento regulatorio, sin ninguna ventaja competitiva real. Construyen lo que la regulación exige, en el tiempo que la regulación impone, y terminan adaptándose a un ecosistema que otros ya diseñaron.
La pregunta correcta es otra: ¿qué podemos construir con Open Finance que antes era imposible?
Esta distinción (entre ver Open Finance como obligación o como infraestructura estratégica) es la que separa a las instituciones que van a liderar la transformación financiera en LATAM de las que van a reaccionar ante ella.
El mapa regulatorio: dónde está cada país y qué implica
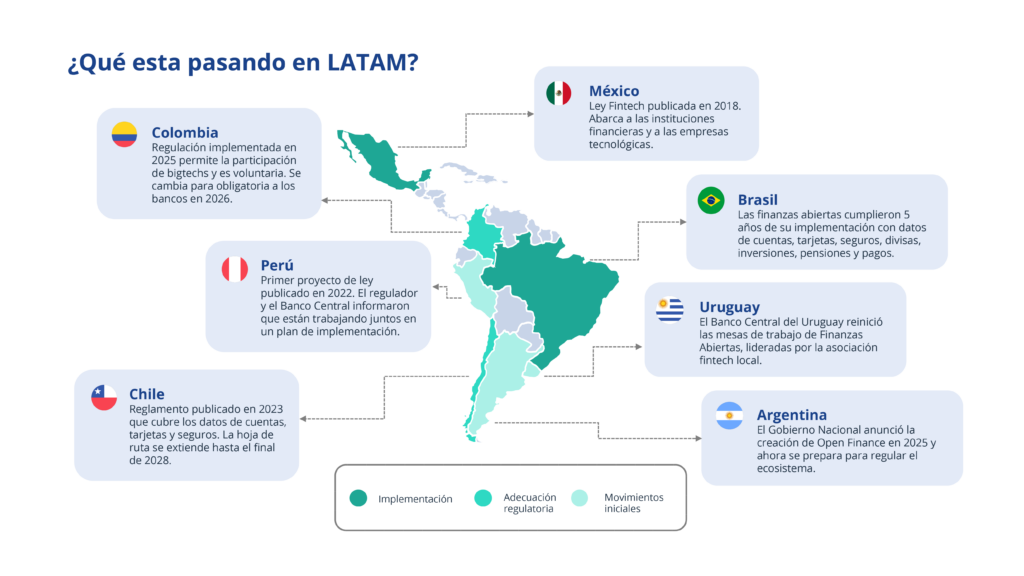
LATAM no es un mercado uniforme en materia de Open Finance. Cada país está en una etapa diferente, con implicaciones distintas para las instituciones que operan en la región.
Brasil lidera con claridad: lleva más de cinco años de implementación con datos de cuentas, tarjetas, seguros, divisas, inversiones, pensiones y pagos. El ecosistema brasileño ya produce casos de uso concretos y medibles. Nubank utilizó datos de Open Finance para ahorrar a sus clientes R$8 millones en intereses en diez meses. Mercado Pago otorgó crédito a más de 30.000 personas, de las cuales el 53% considera que el acceso a sus datos financieros a través de Open Finance fue esencial para obtenerlo.
Colombia implementó su regulación en 2025 con participación voluntaria, pero la obligatoriedad para bancos entra en vigencia en 2026. Chile publicó su reglamento en 2023 con una hoja de ruta que se extiende hasta 2028. Argentina anunció la creación del ecosistema en 2025 y está definiendo la regulación ahora mismo. México tiene la Ley Fintech desde 2018. Perú y Uruguay están en etapas iniciales de planificación.
Lo que el mapa muestra es que la ventana de early mover está en momentos muy diferentes según el mercado. En Brasil ya cerró. En Colombia se está cerrando. En Argentina, Chile y México todavía está abierta. Las instituciones que actúen antes de que la regulación los obligue no solo van a cumplir: van a participar en la definición de los estándares, las integraciones y los modelos de negocio que van a gobernar el ecosistema financiero de la región durante la próxima década.
Lo que Open Finance hace posible que antes era imposible
Open Finance no es una evolución del home banking. Es un cambio de modelo: el paso de ecosistemas cerrados donde las instituciones controlan la información, a economías abiertas donde los datos fluyen de forma segura entre bancos, aseguradoras, fondos de inversión, fintechs y otros participantes autorizados, con el consentimiento explícito del cliente.
Eso habilita modelos de negocio que antes no existían:
- Banking as a Service: cualquier empresa puede ofrecer productos bancarios. Los bancos se convierten en plataformas B2B que proveen infraestructura financiera a terceros.
- Embedded Finance: crédito, seguro y pagos integrados directamente en el retailer, el marketplace o el e-commerce, sin que el cliente tenga que salir de la experiencia que ya está usando.
- Data Marketplace: los datos financieros anonimizados se convierten en un activo comercial. Scoring alternativo, insights de comportamiento, analítica predictiva. Inclusión financiera para segmentos que el modelo tradicional no alcanzaba.
- RegTech integrado: APIs para AML, KYC y detección de fraude que convierten la regulación en ventaja competitiva para las instituciones más ágiles.
Cada uno de estos modelos requiere una base tecnológica que no se construye en semanas. Requiere APIs bien diseñadas, plataformas de consentimiento robustas, arquitecturas que soporten el intercambio seguro de datos entre múltiples actores, y equipos que entiendan tanto la regulación local como los estándares internacionales.
Los tres pilares que hay que resolver al mismo tiempo
La implementación de Open Finance no es un proyecto de tecnología. Es una transformación que exige alinear tres pilares simultáneamente:
Tecnología y datos: ¿cuál es la arquitectura de APIs? ¿Qué estructura de gobierno hace falta? ¿Los datos internos tienen la calidad suficiente para ser compartidos con garantías? Sin una base tecnológica sólida, el resto no escala.
- Estrategia: ¿cuál es el modelo de negocio? ¿Cuáles son las fuentes de ingreso en un ecosistema abierto? ¿Cómo se posiciona la institución frente a fintechs y bigtechs que van a aprovechar el mismo ecosistema? La estrategia define para qué se usa la tecnología.
- Producto y servicio: ¿a qué clientes apuntamos? ¿Cuál es la propuesta de valor concreta? Open Finance solo genera impacto si se traduce en productos que el cliente elige usar.
Y debajo de los tres: cultura. La capacidad de compartir datos, de colaborar con terceros, de repensar la propuesta de valor desde cero, no se instala con una plataforma. Requiere una organización dispuesta a cambiar cómo crea valor.
El momento es ahora
Las organizaciones que actúen durante esta ventana no solo van a cumplir con las regulaciones que vengan. Van a capturar nuevas fuentes de ingreso mediante la monetización de APIs. Van a fidelizar clientes con experiencias personalizadas que un modelo cerrado no puede ofrecer. Van a reducir costos operativos a través de eficiencias de ecosistema. Y van a acumular datos, experiencia y ventaja competitiva que se compone con el tiempo.
Las que esperen van a llegar a un ecosistema que otros ya diseñaron. Y adaptarse a las reglas de un juego que no definiste siempre es más caro y más lento que haberlo jugado desde el principio.
La conversación correcta no empieza con ‘¿cuándo nos obliga la regulación?’. Empieza con ‘¿qué podemos construir ahora que antes era imposible?’. Y esa conversación puede comenzar hoy.

by Huenei IT Services | Sep 16, 2025 | Data
Durante años, el Open Banking fue visto principalmente como un ejercicio de cumplimiento normativo. Regulaciones en Europa, Latinoamérica y partes de Asia establecieron estándares para el intercambio de datos, la interoperabilidad y los derechos del consumidor. Pero a medida que el modelo madura, queda claro que el alineamiento regulatorio es solo el primer paso.
La verdadera oportunidad está en transformar el Open Banking de una obligación legal a una estrategia de crecimiento.
La presión sobre los márgenes bancarios
La industria bancaria global enfrenta una presión sostenida sobre sus márgenes. El aumento de los costos operativos, los mayores requisitos de capital y las crecientes expectativas de clientes digitales están erosionando la rentabilidad. Las palancas tradicionales de eficiencia, como el cierre de sucursales, la automatización de procesos de back office o la reducción de personal, ya no son suficientes para garantizar la resiliencia a largo plazo.
En este contexto, el Open Banking no debe verse como una carga regulatoria más, sino como una palanca estratégica para desbloquear nuevas fuentes de ingresos. Al adoptar ecosistemas de datos abiertos, los bancos pueden diversificar servicios, fortalecer alianzas y monetizar APIs como productos en sí mismos.
Más allá de la tecnología: un cambio en el modelo de negocio
Muchas instituciones aún ven las APIs como “tuberías”. Una necesidad técnica para cumplir con regulaciones o integrarse con socios. Esta visión limitada pierde de vista el verdadero valor: las APIs son canales de distribución. Permiten a los bancos ofrecer productos fuera de sus propias plataformas, llegando a los clientes a través de apps fintech, sistemas corporativos y marketplaces de terceros.
En otras palabras, el Open Banking no solo implica rediseñar sistemas. Implica reimaginar el modelo de negocio:
- Pasar de estrategias centradas en productos a estrategias centradas en ecosistemas.
- Monetizar el acceso a datos como servicio para fintechs, aseguradoras y empresas.
- Construir servicios de valor agregado sobre datos transaccionales, como scoring crediticio, planificación financiera o pagos embebidos.
Este cambio no es opcional. Las empresas que logren posicionarse en el centro del ecosistema digital van a tener una clara ventaja.
En cambio, quienes sigan operando de forma aislada corren el riesgo de perder relevancia frente a un mercado que evoluciona cada vez más rápido.
El auge de las alianzas
Uno de los aspectos más prometedores del Open Banking es la posibilidad de colaborar con fintechs y nuevos jugadores, en lugar de competir directamente.
Asociarse permite a los bancos acelerar la innovación sin reinventar la rueda. Por ejemplo:
- Un banco retail puede integrar una herramienta de gestión financiera personal de una fintech en su app, generando mayor fidelización.
- Un banco corporativo puede conectar sus servicios de tesorería directamente con plataformas ERP, creando experiencias B2B fluidas.
- Un banco universal puede apalancar plataformas fintech de préstamos para ampliar el acceso al crédito en poblaciones desatendidas, manteniendo la gestión del riesgo internamente.
En todos los casos, el modelo de API abierta permite a los bancos ampliar su relevancia a lo largo del recorrido del cliente, manteniendo la confianza como diferencial central.
Rentabilidad en la economía del dato abierto
La magnitud de la oportunidad es clara. A nivel global, hay más de 416.000 millones de dólares en ingresos bancarios en juego con la transición hacia la economía de datos abiertos. Las APIs se están convirtiendo en productos por derecho propio, y los bancos comienzan a cobrar a sus socios por conjuntos de datos premium, analítica avanzada o conectividad en tiempo real.
Ademas, la colaboración refuerza la resiliencia. En lugar de competir contra cada nuevo jugador digital, los bancos pueden convertirse en orquestadores de ecosistemas, ofreciendo más opciones a los clientes y capturando una parte de la innovación de terceros.
Tesorería corporativa e innovación B2B
Aunque gran parte de la conversación sobre Open Banking se enfoca en el segmento retail, los casos de uso corporativos pueden ser igual de transformadores. Las grandes empresas demandan visibilidad en tiempo real de su liquidez, posiciones cross-border y pronósticos de flujo de caja. Las APIs permiten a los bancos conectarse directamente con sistemas de tesorería y ERPs, brindando:
- Gestión de posiciones instantánea en múltiples geografías
- Optimización de liquidez mediante barridos y transferencias automáticas
- Reducción del riesgo operativo al eliminar procesos por lotes y conciliaciones manuales
Estas capacidades generan relaciones sólidas y de alto valor con los clientes corporativos. Esto es una defensa clave frente a la comoditización del negocio minorista.
Actuar con urgencia
Tres de cada cuatro bancos en el mundo esperan que la adopción de Open Banking y el uso de APIs crezca más del 50 % en los próximos años. En Europa, la cantidad de terceros proveedores se cuadruplicó en solo dos años, demostrando la velocidad con que estos ecosistemas pueden escalar cuando la regulación y el mercado se alinean.
Para los bancos en mercados emergentes, la lección es simple: esperar a que la regulación madure no es una estrategia. Las instituciones que adopten una postura proactiva, invirtiendo en gobernanza de datos, monetización de APIs y modelos de alianzas, serán las mejor posicionadas.
La perspectiva de Huenei
En Huenei vemos al Open Banking como un punto de inflexión. Los ganadores serán aquellos que lo traten no como un requisito de compliance, sino como una plataforma para crecer. El éxito requiere:
Integración ágil: APIs que se conectan sin fricción ni interrupciones.
Equipos especializados: squads capaces de modernizar sistemas legados y de incorporar seguridad en todas las capas.
Arquitectura escalable: soluciones que cumplan con los requisitos actuales, pero estén listas para la innovación futura.
En última instancia, el Open Banking es un cambio de modelo: de lo cerrado a lo abierto, de lo centrado en el producto a lo centrado en el ecosistema.
Se trata de transformar la regulación en oportunidad.
Leé el informe completo acá

by Huenei IT Services | Sep 5, 2025 | Data
Una guía práctica sobre Open Banking
Open Banking ya no es solo regulación: se convirtió en la base de la infraestructura financiera moderna. La apertura de datos mediante APIs está transformando la forma en que los bancos se relacionan con clientes, fintechs y corporaciones.
Este informe explora cómo la banca abierta evoluciona hacia un modelo centrado en la experiencia del cliente y en la creación de nuevos modelos de negocio. Ya no se trata solo de cumplir con la normativa, sino de integrar rápido, sin downtime y con equipos preparados para capturar valor.
En este whitepaper vas a encontrar:
- Por qué la experiencia del cliente es hoy el verdadero motor del Open Banking
- Cómo los pagos abiertos están cambiando el checkout digital
- Qué oportunidades de rentabilidad y resiliencia trae la colaboración con fintechs
- Casos de uso corporativos: tesorería y APIs en tiempo real
- La visión práctica de Huenei para acelerar la adopción sin frenar la operación
Una guía clara y accionable para entender cómo pasar del cumplimiento a la generación de valor con Open Banking.
Leé el informe completo acá

by Huenei IT Services | Oct 30, 2024 | Data, Inteligencia Artificial
Data-Driven: Del Enfoque Básico a la Personalización en IA Generativa
El verdadero valor de la IA generativa no está solo en la adopción de soluciones estándar, sino en cómo las empresas personalizan esta tecnología para ajustarla a sus necesidades específicas. Este enfoque no solo mejora los resultados, sino que también genera una ventaja competitiva sostenible y diferenciada.

Tres Niveles de Adopción de la IA Generativa
Una forma de clasificar el uso de la IA generativa en las empresas es a través de tres niveles de adopción: Taker, Shaper y Maker.
En el primer nivel, las empresas Taker implementan soluciones de IA listas para usar. Esto les permite obtener resultados rápidos y a bajo costo, pero sin una adaptación profunda a sus procesos. Aunque facilita la adopción inicial, su impacto a largo plazo es limitado.
En el segundo nivel, las empresas Shaper ajustan los modelos con sus propios datos, mejorando la precisión y el control sobre los resultados. Esto les permite responder mejor a los desafíos específicos del negocio.
Finalmente, en el nivel Maker, las empresas desarrollan o personalizan sus modelos desde cero. Este enfoque ofrece un control total sobre la tecnología, moldeándola completamente según las necesidades del negocio, lo que otorga una flexibilidad y dominio únicos.
Estrategia para Avanzar hacia la Personalización
La personalización de soluciones de IA generativa permite a las empresas alinear los resultados con sus objetivos específicos al utilizar datos internos que reflejan sus procesos únicos. Esto mejora la precisión en la toma de decisiones y optimiza operaciones clave, generando una ventaja competitiva difícil de replicar.
Para avanzar hacia esta personalización, es fundamental garantizar la calidad de los datos internos que alimentan los modelos. El entrenamiento de estos modelos es clave para asegurar la precisión y efectividad de los resultados, ya que dependen de datos relevantes y representativos de los procesos del negocio.
El preprocesamiento de datos es esencial en esta etapa. Procesos como la limpieza, normalización y reducción de dimensionalidad (a través de técnicas como PCA o t-SNE) mejoran la calidad del conjunto de datos y maximizan la capacidad del modelo para detectar patrones precisos. Herramientas como Snowflake y Databricks facilitan la gestión de grandes volúmenes de datos, preparándolos para el entrenamiento.
Plataformas como OpenAI, Google Vertex AI y Azure Machine Learning proporcionan herramientas que permiten ajustar y entrenar los modelos de IA generativa con datos propios. Esto asegura que las soluciones estén personalizadas para enfrentar los desafíos específicos
Desafíos de la Personalización de IA
La transición hacia un uso más avanzado de la IA conlleva varios desafíos. Uno de ellos es la inversión inicial necesaria para implementar la infraestructura de datos y fortalecer el equipo técnico especializado. Aunque los costos iniciales pueden parecer elevados, el retorno en términos de competitividad y eficiencia puede justificar la inversión a largo plazo.
Otro desafío es la gestión técnica de los modelos personalizados. El entrenamiento continuo y la actualización periódica de los modelos es esencial para mantener su relevancia y efectividad, ya que el entorno empresarial cambia constantemente. Si un modelo es entrenado con datos desactualizados o incompletos, su precisión y utilidad se ven comprometidas.
Para las empresas que enfrentan limitaciones de recursos o brechas en habilidades, trabajar con Agile Dedicated Teams puede ser una solución. Estos equipos especializados aportan la flexibilidad y el conocimiento necesario para entrenar, actualizar y optimizar modelos de IA, garantizando su eficiencia en un mercado en rápida evolución.
Para mitigar este riesgo, se deben implementar ciclos de entrenamiento recurrentes y mecanismos de actualización automática. El transfer learning, una técnica que permite reutilizar modelos previamente entrenados para ajustarlos a nuevos conjuntos de datos, puede acelerar este proceso y reducir los costos asociados al entrenamiento.
Además, las prácticas de MLOps (Machine Learning Operations) automatizan el monitoreo y la actualización de los modelos, asegurando que los ciclos de entrenamiento y optimización se mantengan sin interrupciones. Esto no solo reduce la carga operativa, sino que también garantiza que los modelos respondan de manera ágil a las nuevas condiciones del mercado.
Finalmente, la seguridad de los datos y la protección de la propiedad intelectual son cruciales cuando se utiliza información interna para entrenar los modelos. Métodos de encriptación y anonimización deben aplicarse para minimizar riesgos y garantizar el cumplimiento de normativas.
Desarrollo de Modelos a Medida: Control Total en la IA
Algunas empresas optan por ir más allá de la personalización superficial y desarrollan soluciones de IA a medida. Crear modelos desde cero o con un alto grado de personalización les permite tener un control completo sobre su funcionamiento y evolución.
Sin embargo, esto no significa que todo el desarrollo deba hacerse internamente. Muchas organizaciones colaboran con socios tecnológicos que aportan experiencia y recursos especializados, combinando el conocimiento profundo del negocio con las capacidades técnicas del partner. Esta colaboración garantiza que las soluciones de IA sean óptimas y estén alineadas con los objetivos estratégicos.
Aprovechar al Máximo la IA Generativa a través de la Personalización
La personalización de la IA generativa es esencial para las empresas que buscan diferenciarse y maximizar el valor de esta tecnología. Un enfoque estratégico que priorice el entrenamiento de los modelos con datos de alta calidad es clave para asegurar la precisión y efectividad de los resultados.
Ajustar los modelos con datos internos no solo mejora la precisión, sino que también asegura que las soluciones estén alineadas con las necesidades específicas del negocio, proporcionando una ventaja competitiva duradera. Para avanzar hacia una estrategia personalizada, es necesario evaluar la calidad de los datos, fortalecer el equipo técnico y seleccionar los casos de uso más adecuados.
De este modo, las empresas no solo aprovecharán la IA generativa, sino que liderarán la innovación en sus sectores con soluciones tecnológicas diseñadas a medida. ¿Interesado en personalizar tus soluciones de IA generativa? Contáctanos y conversemos sobre cómo podemos ayudar a tu empresa a alcanzar sus objetivos.
 Get in Touch!
Get in Touch!
Francisco Ferrando
Business Development Representative
fferrando@huenei.com

by Huenei IT Services | Oct 1, 2024 | Data, Inteligencia Artificial
Datos sintéticos: una nueva forma de entrenar modelos de IA
El entrenamiento de modelos de inteligencia artificial (IA) requiere grandes volúmenes de datos para alcanzar resultados precisos. Sin embargo, el uso de datos reales plantea riesgos significativos para la privacidad y el cumplimiento normativo.
Para abordar estos desafíos, los datos sintéticos se han convertido en una alternativa viable. Estos son datos generados artificialmente que imitan las características estadísticas de los datos reales, permitiendo a las organizaciones entrenar sus modelos de IA sin comprometer la privacidad de las personas ni incumplir regulaciones.
Cumplimiento normativo, privacidad y escasez de datos
El cumplimiento normativo en torno al uso de datos personales se ha vuelto cada vez más restrictivo con regulaciones como el Reglamento General de Protección de Datos (GDPR) en Europa y la Ley de Privacidad del Consumidor de California (CCPA) en los Estados Unidos.
Los datos sintéticos ofrecen una solución para entrenar modelos de IA sin poner en riesgo información personal, ya que no contienen datos identificables, pero siguen siendo representativos para garantizar resultados precisos.
Casos de uso de los datos sintéticos
El impacto de los datos sintéticos se extiende a diversos sectores donde la protección de la privacidad y la falta de datos reales son desafíos comunes. Veamos cómo esta tecnología está transformando algunas industrias clave:
Salud
En el sector de la salud, los datos sintéticos son cruciales para la investigación médica y el entrenamiento de modelos predictivos. Al generar datos simulados de pacientes, los investigadores pueden desarrollar algoritmos para predecir diagnósticos o tratamientos sin comprometer la privacidad de los individuos.
Los datos sintéticos replican las características necesarias para los análisis médicos sin riesgo de violaciones de privacidad.
Por ejemplo, herramientas como Synthea han generado datos clínicos sintéticos realistas, como SyntheticMass, que contiene información de un millón de residentes ficticios de Massachusetts, replicando tasas reales de enfermedades y visitas médicas.
Finanzas
En el sector financiero, los datos sintéticos permiten a las instituciones mejorar la detección de fraudes y combatir actividades ilícitas. Al generar transacciones ficticias que reflejan las reales, se pueden entrenar modelos de IA para identificar patrones sospechosos sin compartir datos sensibles de los clientes, asegurando el cumplimiento de estrictas normativas de privacidad.
Por ejemplo, JPMorgan Chase emplea datos sintéticos para evitar las restricciones internas de intercambio de datos. Esto le permite entrenar modelos de IA de manera más eficiente mientras protege la privacidad de los clientes y cumple con las regulaciones financieras.
Automotriz
Los datos sintéticos están desempeñando un papel crucial en el desarrollo de vehículos autónomos al crear entornos de conducción virtuales. Estos conjuntos de datos permiten entrenar modelos de IA en escenarios que serían difíciles o peligrosos de replicar en el mundo real, como condiciones climáticas extremas o comportamientos inesperados de los peatones.
Un ejemplo destacado es Waymo, que utiliza datos sintéticos para simular escenarios de tráfico complejos. Esto les permite probar y entrenar sus sistemas autónomos de manera segura y eficiente, reduciendo la necesidad de pruebas físicas costosas y que consumen mucho tiempo.
Generación y uso de datos sintéticos
La generación de datos sintéticos se basa en técnicas avanzadas como redes generativas antagónicas (GANs), algoritmos de aprendizaje automático y simulaciones por computadora. Estos métodos permiten a las organizaciones crear conjuntos de datos que reflejan escenarios del mundo real, al mismo tiempo que se preserva la privacidad y se reduce la dependencia de fuentes de datos sensibles o escasas.
Los datos sintéticos también pueden escalarse de manera eficiente para satisfacer las necesidades de grandes modelos de IA, lo que permite una generación rápida y rentable de datos para diversos casos de uso.
Por ejemplo, plataformas como NVIDIA DRIVE Sim utilizan estas técnicas para crear entornos virtuales detallados destinados al entrenamiento de vehículos autónomos. Al simular desde condiciones meteorológicas adversas hasta escenarios complejos de tráfico urbano, NVIDIA facilita el desarrollo y la optimización de tecnologías de IA sin depender de pruebas físicas costosas.
Desafíos y limitaciones los datos sintéticos
Uno de los principales retos es garantizar que los datos generados representen con precisión las características de los datos reales. Si no son lo suficientemente representativos, los modelos entrenados podrían fallar al enfrentarse a datos reales. Además, los sesgos presentes en los datos originales pueden replicarse en los datos sintéticos, lo que afecta la precisión de las decisiones automatizadas.
Esto requiere una supervisión constante para detectar y corregir esos sesgos. A pesar de ser útiles en entornos controlados, los datos sintéticos no siempre capturan la complejidad del mundo real, lo que limita su efectividad en escenarios dinámicos o complejos.
Para organizaciones en estos sectores, contar con un socio tecnológico especializado puede ser clave para encontrar soluciones efectivas y adaptadas a sus necesidades.
El creciente papel de los datos sintéticos
Los datos sintéticos son solo una de las herramientas disponibles para proteger la privacidad mientras se entrena IA. Otras formas incluyen el uso de técnicas de anonimización de datos, donde se eliminan detalles personales sin perder información relevante para el análisis.
También están ganando relevancia enfoques como el aprendizaje federado, que permite entrenar modelos de IA utilizando datos descentralizados sin necesidad de moverlos a una ubicación central. Además, el potencial de los datos sintéticos se extiende más allá del entrenamiento de modelos.
Estos datos pueden utilizarse para mejorar la validación y prueba de software, simular mercados y comportamientos de usuarios, o incluso para el desarrollo de aplicaciones en inteligencia artificial explicativa, donde los modelos son capaces de justificar sus decisiones en base a escenarios generados artificialmente.
A medida que las técnicas para generar y controlar datos sintéticos continúan evolucionando, estos datos desempeñarán un rol aún más importante en el desarrollo de soluciones de IA más seguras y eficaces.
La capacidad de entrenar modelos sin comprometer la privacidad, junto con nuevas aplicaciones que aprovechan los datos generados artificialmente, permitirá a las empresas explorar nuevas oportunidades sin los riesgos asociados al uso de datos reales.
¿Estás listo para explorar cómo podemos ayudarte a proteger la privacidad y optimizar la implementación de IA en tu organización? Hablemos.
 Get in Touch!
Get in Touch!
Isabel Rivas
Business Development Representative
irivas@huenei.com
