
Los datos se han convertido en un elemento vital para las empresas digitales, y una ventaja competitiva clave, pero el volumen de datos que actualmente necesitan administrar las organizaciones es muy heterogéneo y su velocidad de crecimiento exponencial. Surge así la necesidad de soluciones de almacenamiento y análisis, que ofrezcan escalabilidad, rapidez y flexibilidad para poder gestionar esta masiva cantidad de datos. ¿Cómo es posible almacenarlos de manera rentable y acceder a ellos rápidamente? Un Data Lake (Lago de Datos) es una respuesta moderna a este problema.
En esta serie de artículos, veremos qué es un Data Lake, cuáles son sus beneficios y cómo podemos implementarlo utilizando Amazon Web Services (AWS).
¿Qué es un Data Lake?
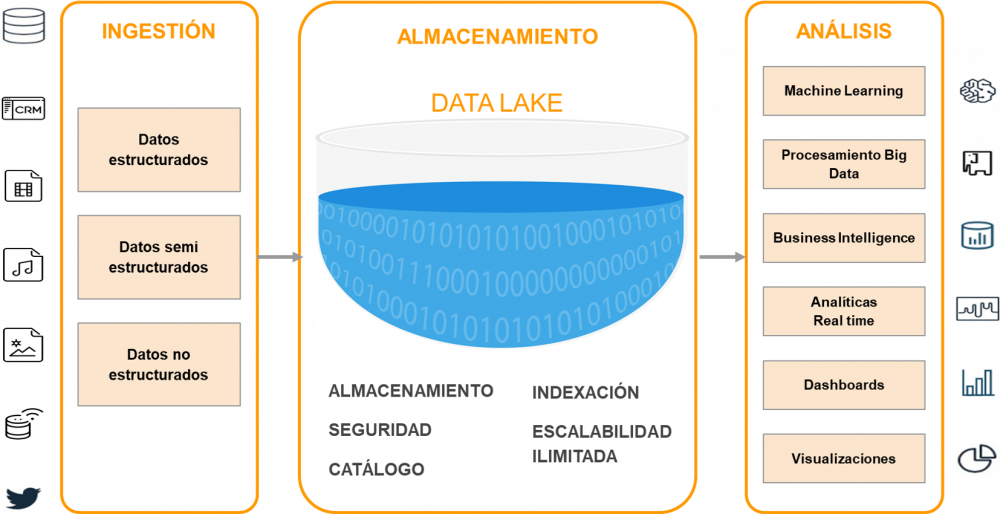
Un Data Lake es un repositorio de almacenamiento centralizado, que permite guardar todo tipo de datos estructurados o no, a cualquier escala, sin procesar, hasta que se los necesite. Cuando surge una pregunta de negocio, es posible obtener la información relevante y ejecutar diferentes tipos de análisis sobre ella, a través de dashboards, visualizaciones, procesamiento de Big Data y aprendizaje automático, para guiar la toma de mejores decisiones.
Un Data Lake puede almacenar datos tal como están, sin tener que estructurarlos primero, con poco o ningún procesamiento, en sus formatos nativos, tales como JSON, XML, CSV o texto. Puede almacenar tipo de archivos: imágenes, audios, videos, weblogs, datos generados desde sensores, dispositivos IoT, redes sociales, etc. Algunos formatos de archivo son mejores que otros, como Apache Parquet que es un formato columnar comprimido que proporciona un almacenamiento muy eficiente. La compresión ahorra espacio en disco y accesos de E/S, mientras que el formato permite al motor de consultas escanear sólo las columnas relevantes, lo cual reduce el tiempo y los costos de las mismas.
El uso de un sistema de archivos distribuido (DFS), como AWS S3, permite almacenar más datos a un costo menor, brindando múltiples beneficios:
- Replicación de datos
- Altísima disponibilidad
- Bajos costos, con diferentes escalas de precios y múltiples tipos de almacenamiento dependientes del tiempo de recuperación (desde acceso instantáneo a varias horas)
- Políticas de retención, lo que permite especificar cuánto tiempo conservar los datos antes de que se eliminen automáticamente
Data Lake versus Data Warehouse
Los Data Lakes y los Data Warehouses son dos estrategias diferentes de almacenar Big Data, en ambos casos sin atarse a una tecnología específica. La diferencia más importante entre ellos es que, en un Data Warehouse, el esquema de datos está preestablecido; se debe crear un esquema y planificar las consultas. Al alimentarse de múltiples aplicaciones transaccionales en línea, se requiere que los datos se transformen vía ETL (extraer, transformar y cargar) para que se ajusten al esquema predefinido en el almacén de datos. En cambio, un Data Lake puede albergar datos estructurados, semi-estructurados y no estructurados y no tiene un esquema predeterminado. Los datos se recogen en estado natural, necesitan poco o ningún procesamiento al guardarlos y el esquema se crea durante la lectura para responder a las necesidades de procesamiento de la organización.
El Data Lake es una solución más flexible y adaptada a usuarios con perfiles más técnicos, con necesidades de análisis avanzadas, como Científicos de Datos, porque se necesita un nivel de habilidad para poder clasificar la gran cantidad de datos sin procesar y extraer fácilmente el significado de ellos. Un almacén de datos se centra más en usuarios de Análiticas de Negocios, para respaldar las consultas comerciales de grupos internos específicos (Ventas, Marketing, etc.), al poseer los datos ya curados y provenir de los sistemas operacionales de la empresa. Por su parte, los Data Lakes suelen recibir datos tanto relacionales como no relacionales de dispositivos IoT, redes sociales, aplicaciones móviles y aplicaciones corporativas.
En lo que respecta a la calidad de los datos, en un Data Warehouse, estos están altamente curados, son confiables y se consideran la versión central de la verdad. En cambio, en un Data Lake son menos confiables porque podrían llegar de cualquier fuente en cualquier estado, curados o no.
Un Data Warehouse es una base de datos optimizada para analizar datos relacionales, provenientes de sistemas transaccionales y aplicaciones de línea de negocios. Suelen ser muy costosos para grandes volúmenes de datos, aunque ofrecen tiempos de consulta más rápidos y mayor rendimiento. Los Data Lakes, en cambio, están diseñados pensando en el bajo costo de almacenamiento.
Algunas críticas legítimas que reciben los Data Lakes son:
- Es aún una tecnología emergente frente el modelo de madurez fuerte de un Data Warehouse, el cual posee muchos años en el mercado.
- Un Data Lake podría convertirse en un “pantano”. Si una organización practica una deficiente gestión y gobernanza, puede perder el rastro de lo que existe en el “fondo” del lago, provocando su deterioro, volviéndolo incontrolado e inaccesible.
Debido a sus diferencias, las organizaciones pueden optar por utilizar tanto un Data Warehouse como un Data Lake en una implementación híbrida. Una posible razón sería el poder agregar nuevas fuentes o usar el Data Lake como repositorio para todo aquello que ya no se necesite en el almacén de datos principal. Con frecuencia, los Data Lakes son una adición o una evolución de la estructura de administración de datos actual de una organización en lugar de un reemplazo. Los Analistas de Datos pueden hacer uso de vistas más estructuradas de los datos para obtener sus respuestas y, a la vez, la Ciencia de Datos puede «ir al lago» y trabajar con toda la información en bruto que sea necesaria.
Arquitectura de un Data Lake
La arquitectura física de un Data Lake puede variar, ya que se trata de una estrategia aplicable por múltiples tecnologías y proveedores (Hadoop, Amazon, Microsoft Azure, Google Cloud). Sin embargo, hay 3 principios que lo distinguen de otros métodos de almacenamiento Big Data y constituyen la arquitectura básica de un Data Lake:
- No se rechaza ningún dato. Se cargan desde varios sistemas de origen y se conservan.
- Los datos se almacenan en un estado sin transformar o casi sin transformar, tal como se recibieron de la fuente.
- Los datos se transforman y se ajustan al esquema durante el análisis.
Si bien la información, en gran medida, no está estructurada ni orientada a responder una pregunta específica, debe ser organizada de alguna manera, para garantizar que el Data Lake sea funcional y saludable. Algunas de estas características incluyen:
- Etiquetas y/o metadata para la clasificación, que puede incluir tipo, contenido, escenarios de uso y grupos de posibles usuarios.
- Una jerarquía de archivos con convenciones de nomenclatura.
- Un Catálogo de datos indexado y con capacidad de búsqueda.
Conclusiones
Los Data Lakes son cada vez más importantes para las estrategias de datos empresariales. Responden mucho mejor a la realidad actual: volúmenes y tipos de datos mucho mayores, mayores expectativas de los usuarios y mayor variedad de analíticas, tanto de negocio como predictivas. Tanto los Data Warehouses como los Data Lakes están destinados a convivir en las empresas que deseen basar sus decisiones en datos. Ambos son complementarios, no sustitutivos, pudiendo ayudar a cualquier negocio a conocer mejor el mercado y al consumidor, e impulsar iniciativas de transformación digital.
En el próximo artículo, analizaremos cómo podemos utilizar Amazon Web Services y su infraestructura abierta, segura, escalable y rentable, para construir Data Lakes y analíticas sobre ellos.