
En nuestro artículo anterior “Aceleración por Hardware con FPGAs”, conocimos qué son los dispositivos lógicos programables denominados FPGA (Field-Programmable Gate Array del inglés), discutimos su uso como compañero de los CPU para lograr esta aceleración y nombramos algunas ventajas de uso frente a los GPU (Graphics Processing Unit del inglés).
Para tener una mejor noción, nos adentraremos en los aspectos técnicos para entender cómo funcionan en líneas generales, desde cómo se logra la aceleración o cómo se accede a la tecnología, hasta algunas consideraciones para su utilización con una solución de software.
Conceptos clave
Las dos principales razones por las cuales las FPGAs tienen un mayor rendimiento que los CPUs, serían la posibilidad de utilizar hardware a medida y su gran poder de paralelismo.
Tomemos como ejemplo el realizar una suma de 1.000 valores, en el caso de los CPU, que están compuestos por un hardware fijo de propósito general, el proceso comenzaría con el almacenamiento de los valores en la memoria RAM, posteriormente pasan a la memoria interna de rápido accesos (memoria Caché) donde serán tomados para cargar dos registros.
Tras la configuración de la Unidad Aritmética Lógica (ALU) para lograr la operación deseada, se realiza una suma parcial de estos 1.000 valores y se almacena el resultado en un tercer registro. Luego, se toma un nuevo valor, se carga el resultado parcial obtenido en el punto anterior y se vuelve a realizar la operatoria.
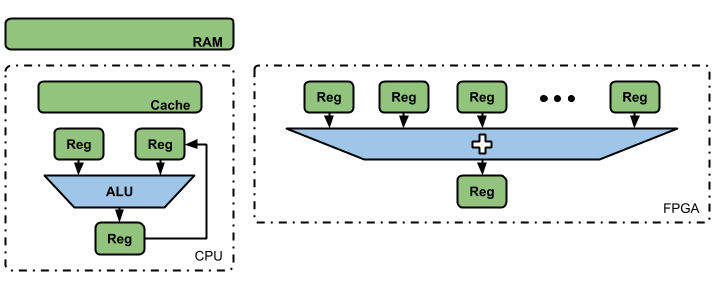
Tras la última iteración, el resultado final se guarda en la memoria Caché donde la información estará accesible en caso de que sea requerida posteriormente, almacenandose en la RAM del sistema para ser un valor consolidado del programa en ejecución. En el caso de una FPGA, todo el ciclo anterior se reduce a 1.000 registros, donde sus valores se suman directamente al mismo tiempo.
Debemos tener en cuenta que, en ocasiones, la FPGA tendrá que leer valores desde una memoria RAM del sistema, encontrándose en una situación similar a la del CPU. Sin embargo, la ventaja ante los CPU viene dada en que este no tiene 1.000 registros de propósito general que se le pueda dar el uso exclusivo de almacenar los valores para una suma. Por el contrario, un CPU tiene pocos registros disponibles para ser compartidos en la realización de distintas operatorias.
Un ejemplo para entender la potencia y aceleración de las FPGAs sería el de visualizar que contamos con un bucle de cinco instrucciones en la memoria de programa del CPU, toma un dato de memoria, lo procesa y lo devuelve. Esta ejecución sería secuencial, una instrucción por lapso de tiempo, obligándolos a llegar a la última para poder volver a empezar el proceso.
En una FPGA, el equivalente a cada una de las instrucciones del CPU se puede ejecutar en un bloque en paralelo, alimentando la entrada de cada uno con la salida anterior.
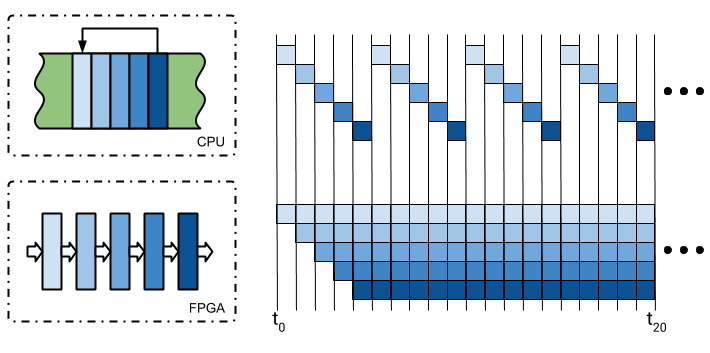
Como podemos observar en la imagen, vemos que el tiempo transcurrido hasta obtener el primer dato es el mismo en ambos casos, sin embargo, el período en que se consiguen 4 resultados en un CPU se consigue hasta 16 en el FPGA.
Si bien es un ejemplo didáctico, tengamos en cuenta que, gracias al hardware a media con el que se pueden configurar las FPGAs, la aceleración podría llegar a ser de hasta cientos o miles de veces en una implementación real.
¿Cuándo vale la pena acelerar un proceso?
Por lo expuesto, surge la pregunta ¿por qué entonces no acelerar siempre cualquier proceso? Es más, ¿por qué no reemplazar a los CPUs por FPGAs? Si bien hay casos donde es necesario y se hace, trabajar exclusivamente con FPGAs es mucho más complejo y costoso. Además, los CPU son excelentes y están optimizados para su propósito, lo que los hace perfectos para la mayoría de las tareas de una PC.
Hay que considerar que las FPGAs utilizadas como aceleradores que acompañan a un CPU se extendió en los últimos años. Por un lado, gracias a las altas tasas de transferencia alcanzadas por el protocolo PCI Express (utilizado en la PC para interconectar los dos dispositivos en cuestión).
Por el otro, dadas las velocidades y capacidad de almacenamiento ofrecidas por las memorias DDR. Para qué acelerar tenga sentido, la cantidad de datos involucrados tiene que ser tal de manera que valga la pena todo el proceso de moverlos al acelerador. Por otra parte, debemos estar en presencia de un algoritmo matemático complejo, donde cada paso precise los resultados del paso anterior, capaz de ser dividido y paralelizable.
El Hardware necesario para la aceleración
Los dos principales fabricantes de FPGAs, Xilinx e Intel, ofrecen una variedad de tarjetas aceleradoras, denominadas Alveo y PAC respectivamente, que se conectan a los buses PCI Express de un servidor.
Al momento de querer incluirlas en nuestra infraestructura debemos considerar las especificaciones del equipo servidor receptor, así como las configuraciones del sistema y las licencias del software de desarrollo.

Existen servicios, como el de Amazon, que ofrecen de manera elástica imágenes de desarrollo listas para usarse, así como también instancias del hardware de Xilinx. Tengamos en cuenta que también existen otros servicios, como Microsoft Azure cuyas instancias están basadas en dispositivos Intel, o en el caso de Nimbix, con soporte de ambas plataformas, por nombrar algunos.
Utilización de aceleradores
El desarrollo de aceleradores es una tarea asociada al diseño de circuitos que involucra la utilización de un Hardware Description Language (HDL), aunque puede usarse alternativamente el High Level Synthesis (HLS), un subset del lenguaje C/C++. Finalmente, se puede usar OpenCL al igual que en el desarrollo de aceleradores para GPUs. Usualmente este tipo de tecnologías vincula a especialistas en Ingeniería Electrónica como expertos en programación.
Afortunadamente, tanto proveedores de la tecnología como third-parties, ofrecen aceleradores para algoritmos conocidos y de uso extendido, listos para usar. Las aplicaciones de software aceleradas, están escritas en C/C++, pero hay APIs disponibles para otros lenguajes, como Python, Java o Scala.
En caso de necesitar realizar alguna optimización adicional, hará falta convertir aplicaciones de C/C++ en un cliente/servidor, crear un plugin o realizar un binding. Además, existen también frameworks y librerías listas para usar sin cambios desde la aplicación, relacionadas a Machine Learning, procesamiento de imágenes y video, bases de datos SQL y noSQL, entre otras.
Conclusiones
Desde Huenei, podemos acompañarlo a través de la adopción de esta tecnología. Tras el análisis de su aplicación, podemos ofrecerle la infraestructura que mejor se adapte a sus procesos. Una opción es la asesoría en la utilización de frameworks, librerías y soluciones aceleradas disponibles, que no precisan cambios en el código fuente.
Otra alternativa, es la refactorización empleando un API especial con aceleradores a medida, o directamente iniciar desarrollos con vistas al empleo de estas soluciones. En cualquier caso, contará con la guía de especialistas al tanto de las últimas tendencias en esta temática, tan necesaria para poder hacer frente a los desafíos de datos con crecimiento exponencial y la utilización de algoritmos computacionalmente complejos.