
In our previous article “Hardware Acceleration with FPGAs“, we learned about what programmable logic devices are called FPGAs (Field-Programmable Gate Array), discussed their use as a companion to CPUs to achieve this acceleration, and named some advantages of use versus GPUs (Graphics Processing Unit).
To get a better idea, we will delve into the technical aspects to understand how they generally work, from how acceleration is achieved or how technology is accessed, to some considerations for its use with a software solution.
Key concepts
The two main reasons why FPGAs have higher performance than CPUs would be the possibility of using custom hardware and its great parallelism power.
Let’s take as an example to perform a sum of 1,000 values, in the case of CPUs, which are made up of fixed general-purpose hardware, the process would begin with the storage of the values in RAM memory, then they pass to the internal memory of quick accesses (memory Cache) where they will be taken to load two registers.
After configuring the Logical Arithmetic Unit (ALU) to achieve the desired operation, a partial sum of these 1,000 values is performed and the result is stored in a third register. Then, a new value is taken, the partial result obtained in the previous point is loaded and the operation is performed again.
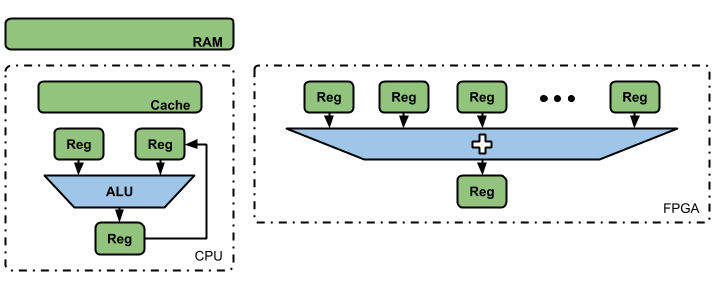
After the last iteration, the final result is saved in the Caché memory where the information will be accessible in case it is required later, being stored in the system RAM to be a consolidated value of the running program. In the case of an FPGA, the entire previous cycle is reduced to 1,000 registers, where their values are directly added at the same time.
We must bear in mind that, sometimes, the FPGA will have to read values from a system RAM memory, finding itself in a situation similar to that of the CPU. However, the advantage over CPUs is that it does not have 1,000 general-purpose registers that can be given the exclusive use of storing values for a sum. In contrast, a CPU has few registers available to be shared in performing different operations.
An example to understand the power and acceleration of FPGAs would be to visualize that we have a loop of five instructions in the CPU’s program memory, it takes data from memory, processes it and returns it. This execution would be sequential, an instruction per time-lapse, forcing them to get to the last one in order to start the process again.
In an FPGA, the equivalent of each of the CPU instructions can be executed in a parallel block, feeding each input with the previous output.
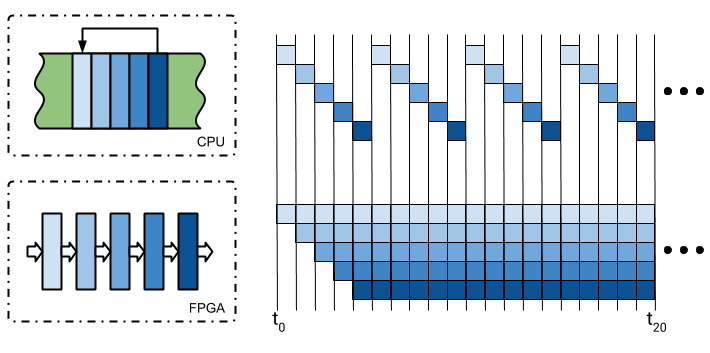
As we can see in the image, we see that the time elapsed until the first data is obtained is the same in both cases, however, the period in which 4 results are achieved in a CPU is achieved up to 16 in the FPGA.
Although it is a didactic example, keep in mind that, thanks to the average hardware with which FPGAs can be configured, the acceleration could be up to hundreds or thousands of times in a real implementation.
It should be noted that FPGAs used as accelerators that accompany a CPU has spread in recent years. On the one hand, thanks to the high transfer rates achieved by the PCI Express protocol (used on the PC to interconnect the two devices in question).
On the other, given the speeds and storage capacity offered by DDR memories. For what accelerating makes sense, the amount of data involved has to be such that it is worth the entire process of moving it to the accelerator. On the other hand, we must be in the presence of a complex mathematical algorithm, where each step requires the results of the previous step, capable of being divided and parallelizable.
The Hardware Needed for Acceleration
The two main manufacturers of FPGAs, Xilinx, and Intel, offer a variety of accelerator cards, called Alveo and PAC respectively, that connect to the PCI Express buses of a server.
When wanting to include them in our infrastructure, we must consider the specifications of the receiving server equipment, as well as the system configurations and licenses of the development software.

There are services, such as Amazon, that offer ready-to-use development images elastically, as well as instances of Xilinx hardware. Keep in mind that there are also other services, such as Microsoft Azure whose instances are based on Intel devices, or in the case of Nimbix, with support from both platforms, to name a few.
Using accelerators
Accelerator development is a task associated with a circuit design that involves the use of a hardware description language (HDL), although you can alternatively High-Level Synthesis (HLS), a subset of the C / C ++ language. Finally, OpenCL can be used just like in developing GPU accelerators. Usually, this type of technology is binding on Electronic Engineering specialists such as programming experts.
Fortunately, both technology providers and third-parties offer ready-to-use accelerators for known and widely used algorithms. Accelerated software applications are written in C / C ++, but there are APIs available for other languages, such as Python, Java, or Scala.
In case you need to perform any additional optimization, you will need to convert C / C ++ applications on a client/server, create a plugin, or perform a binding. In addition, there are also frameworks and libraries ready to use without changes from the application, related to Machine Learning, image, and video processing, SQL and NoSQL databases, among others.
Summary
From Huenei, we can accompany you through the adoption of this technology. After analyzing your application, we can offer you the infrastructure that best suits your processes. One option is advice on the use of available frameworks, libraries, and accelerated solutions, which do not require changes to the source code.
Another alternative is refactoring using a special API with custom accelerators, or directly initiating developments with a view to using these solutions. In any case, you will have the guide of specialists who are up to date with the latest trends in this area, which are so necessary in order to face the challenges of data with exponential growth and the use of computationally complex algorithms.